데이터베이스 Index란?
Database Index란?
INDEX란 RDBMS에서 검색속도를 높이기 위해 사용하는 하나의 기술이다. (SELECT 쿼리의 where이나 join을 사용했을 때만, 인덱스를 사용되며 SELECT 쿼리의 검색 속도를 빠르게 하는 것이 목적이다!)
INDEX는 색인이다. 해당 Table의 컬럼을 색인화(따로 파일로 저장함)하여 검색시 해당 Table의 레코드를 Full Scan하는 것이 아니라, 색인화 되어있는 INDEX 파일을 검색하여 검색 속도를 빠르게 하는 것이다.
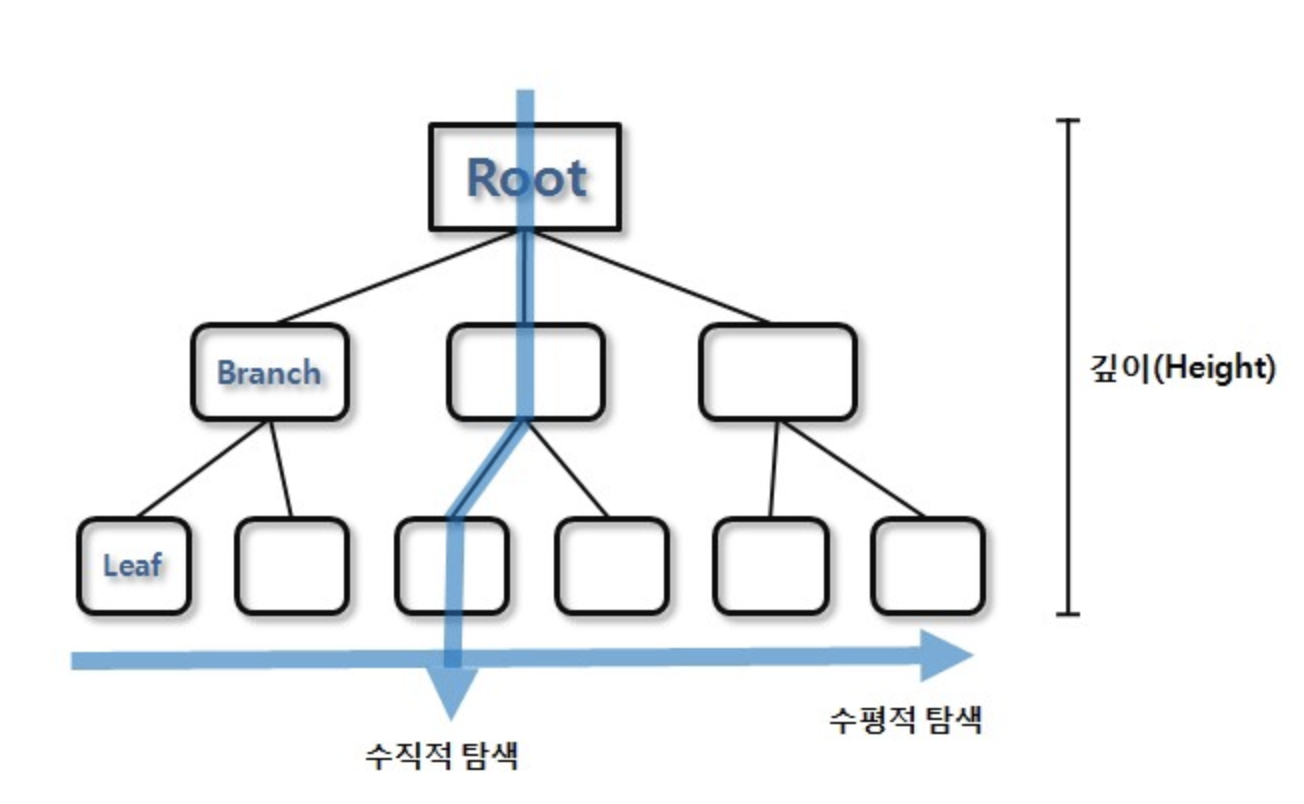
이런 INDEX는 트리 구조로 색인화 한다. RDBMS에서 사용하는 INDEX는 Balanced Search Tree를 사용한다.
실제로 RDBMS에서 사용되는 B-Tree는 B-tree에서 파생된 B+Tree 를 사용한다고 한다.
(Oracle이나 MSSQL의 경우는 여러 종류의 Tree를 선택하여 사용가능하다)
Index의 원리 - 빠른 서비스 제공
INDEX를 해당 컬럼에 추가하게 되면, 초기 TABLE 생성시 만들어진 MYD, MYI,FRM 3개의 파일중에서 MYI에 해당 컬럼을 색인화하여 저장합니다. 물론 INDEX를 사용안할시에는 MYI파일은 비어있습니다. 그래서 INDEX를 해당 컬럼에 만들게되면, 따로 인덱싱하여 MYI파일에 입력한다.
MYI 파일이란? MYI파일은 MyISAM(MySQL 관계형 데이터베이스 관리시스템의 기본 스토리지 엔진이다)의 파일로, 헤더 정보를 저장하는 파트와 키 벨류를 저장하는 두 가지 파트로 구분된다. MYI 파일은 데이터베이스의 Index정보가 들어가있는 파일이다. MYI파일의 헤더는 파일사이즈나 Key에 대한 정보와 옵션에 관한 정보로 구성된다. Key에 대한 데이터는 사용자가 CREATE [UNIQUE] INDEX를 통해서 만들었을 때 쌓인다.
사용자가 SELECT 쿼리를 이용하여 테이블에서 데이터를 조회하려고 할 때, INDEX가 사용되는 쿼리를 사용할 시 테이블을 조회하는 것이 아니라 빠른 TREE로 정리해둔 MYI파일의 내용을 검색한다. (책의 뒷부분에 찾아보기와 같은 개념으로, 단어중에서 원하는 단어를 찾아 페이지수를 보고 쉽게 찾을 수 있는 개념과 같다)
Index의 장점?
- 키값을 기반으로, 테이블에서 검색과 정렬 속도를 향상시킨다.
- 질의나 보고서에서 그룹화 작업의 속도를 향상시킨다. - (DB에서 Groupby를 쓸 때, 예를들어 반별로 정렬할 .)
- 테이블의 기본키는 자동으로 인덱스된다(모델 구성을 할때, 프라이머리키를 설정하면 그 즉시 프라이머리키 기반 인덱스가 생성된다)
- 데이터 형식으로 인해 인덱스 될 수 없는 필드도 존재한다 - ?
- 다중 필드 인덱스를 사용하면, 첫 필드값이 같은 레코드도 구분할 수 있다.
인덱스가 정렬된 데이터인데, 이 아이를 어떤 기준으로 정렬할 것인지 -> 이 기준이 하나면, 단일 필드 인덱스고 여러개면 다중 필드 인덱스다.
어떤 필드를 먼저 사용하는지가 굉장히 중요한 요소가 되는데, 어느 필드를 먼저 드라이빙할지 결정하는 것이 인덱스 성능을 좌우한다.
- 카드널리티(데이터 중복도에 의해 결정, 중복도가 높으면 카디널리티가 낮다, 중복도가 낮으면 카드널리티가 높다)가 높을수록, 이분탐색의 경우 더 많은 데이터를 제끼고 검색할 수 있어서, 카드널리티가 높은 것을 기준으로 인덱싱하는 것이 좋다.
인덱스의 리프노드는 항상 테이블의 실제 레코드를 찾아가기 위한 주소값을 항상 가지고 있다.
Index의 단점?
- 인덱스를 만들면, .mdb 파일 크기가 늘어난다.
- 여러 사용자 응용프로그램에서의 여러 사용자가 한 페이지를 동시에 수정할 수 있는 병행성이 줄어든다. (IF, 한 사용자가 특정 레코드를 수정할 때 인덱스를 사용하는 레코드라면 해당 테이블과 인덱스를 모두 수정해야해서 최소 lock을 2번 걸어주어야 한다. 그렇게 되면 다른 유저가 같은 데이터를 수정하게 되면, 수정시간이 지연되기 때문)
- 인덱스된 필드에서 데이터를 업데이트하거나, 레코드를 추가 또는 삭제할 때 성능이 떨어진다. 추가는 성능이 확실히 떨어지지만, 삭제나 수정의 경우엔 그렇게 성능이 떨어질 것 같지 않다! => 데이터가 100만건이라고 할 때는, 순차적으로 찾아서 수정 및 삭제를 할때, O(100만)인데, 인덱스를 사용함으로써 O(log100만)임으로 성능이 오히려 인덱스를 사용하는 것이 나을 것 같다.
-
인덱스가 데이터베이스 공간을 차지하기 때문에, 추가적인 공간이 필요하다.(실제로 DB 테이블의 10퍼센트 내외의 공간이 추가로 필요)
- 인덱스를 생성하는데 시간이 많이 소요될 수 있다.
- 데이터 변경 작업이 자주 일어날 경우에, 인덱스를 재작성해야 할 필요가 있기 때문에 성능에 영향을 끼칠 수 있다.(테이블 구조가 자주 바뀌는 경우) : 인덱스의 정렬 상태가 달라질 수 있기 때문!
인덱스를 사용할 때는!
- 어느 필드를 인덱스해야 하는지 미리 시험해보고 결정하는 것이 좋다. 인덱스를 추가하면 쿼리 속도가 1초정도 빨라지지만, 데이터 행을 추가하는 속도는 2초정도 느려지게 되어 여러 사용자가 사용하는 경우 레코드 잠금 문제가 발생할 수 있다
- 다른 필드에 대한 인덱스를 만들게 되면, 성능이 별로 향상되지 않을 수 있다. ex) 테이블에 회사 이름 필드와 성 필드가 이미 인덱스 된 경우, 우편 번호 필드를 추가로 인덱스에 포함해도 성능이 거의 향상되지 않는다. 만드는 쿼리의 종류와 관계없이 가장 고유한 값을 갖는 필드만 인덱스해야한다.
인덱스 주의사항
Database Manipulation Language : DML - Insert, Delete, Update, Select에 취약한 인덱스!
-
INSERT
Index split(인덱스의 Block들이 하나에서 두 개로 나누어지는 현상) 현상이 발생할 수 있다. 인덱스는 데이터가 순서대로 정렬되어야 한다. 기존 블록에 여유 공간이 없는 상황에서 그 블록에 새로운 데이터가 입력되어야 할 경우, Oracle이 기존 블록의 내용 중 일부를 새 블록에 기록한 후 기존 블록에 빈 공간을 만들어서 새로운 데이터를 추가한다.
👉 성능면에서 매우 불리하다!
- Index split은 새로운 블록을 할당받고, Key를 옮기는 복잡한 작업을 수행한다. 모든 수행과정이 Redo에 기록되고, 많은 Redo의 양을 유발하게 된다. (공간적인 성능에서 불리)
- Index split이 이루어지는 동안, 해당 블록에 대해 키 값이 변경되면 안되므라 DML이 Blocking 된다.(시간적인 성능에서 불리)
-
DELETE
테이블에서 데이터가 Delete될 경우, 지워지고 다른 데이터가 그 공간을 사용가능하다. Index에서 데이터가 delete될 경우, 데이터가 지워지지 않고 사용안됨 표시만 해둔다.
👉 즉 테이블에 데이터가 1만건이어도, 인덱스에는 2만건이 존재할 수 있다. - 수행속도 저하
-
UPDATE
테이블에 update가 발생할 경우, 인덱스에서는 delete를 하고 새로운 작업의 insert 작업이 발생한다.
👉 Delete와 Insert 두 작업이 동시에 발생하여 DML보다 더 큰 부하를 주게된다.
타 SQL 실행에 악영향을 줄 수 있음
갑자기 인덱스를 추가하면, 잘 돌아가고 있던 쿼리에 옵티마이저가 실행계획을 바꾸는 경우가 생겨, 갑자기 아주 느려지는 경우가 있다.
👉 기존의 테이블에 인덱스를 추가할 경우, 기존 SQL문장들을 전부 고려한 다음 인덱스를 생성해야한다.
(Database Definition Language : DDL - Create)
Index의 세 가지 저장방식
1. B-Tree Index
- 가장 일반적으로 사용되는 인덱스 알고리즘이다.
- 가장 오래된 알고리즘인만큼, 성숙한 안정된 상태의 저장방식이다.
- 컬럼값을 변형하지 않고, 원래 값을 기준으로 인덱싱한다.
2. Hash Index
- 컬럽값을 해시값으로 계산하여 인덱싱하는 알고리즘이다. 매우 빠른 속도를 지원한다.
- 컬럼값이 해시값으로 변형되어 인ㄷ게싱에 활용되기 때문에, 컬럼값의 일부분을 검색하는 경우가 불가능하다.
- 주로 메모리 기반의 데이터베이스에서 많이 사용된다.
3. Fractal-Tree Index
- B-tree Index의 단점을 보완하기 위해 고안된 알고리즘이다.
- B-Tree처럼 컬럼값을 변형하지 않고 인덱싱한다.
- 데이터가 저장되거나 삭제될때, 처리하는 비용을 줄일 수 있게 설계되어있어서 B-tree보다 경제적이지만, 아직 성숙하지 않은 알고리즘이다.
참고자료
DB Index란? : lalwr의 블로그
MYI 파일이란? : MySQL Documentation