Celery with PostgreSQL
Celery란?
웹서버가 처리하기엔 무거운 연산을 그냥 서버에 짜면 사용자는 웹서버의 처리가 끝날 때까지 연산이 돌아가는 웹 브라우저를 하염없이 기다려야 한다.
왜냐하면 Django의 웹서버는 동기적(synchronous)이기 때문이다.
반면 비동기적(asynchrounous) 작업 은 작업을 서버에 던져주고 이를 백그라운드에서 실행시켜 해당 작업이 끝나기를 기다리지 않고 다른 작업을 수행할 수 있다.
ex) JAVA Script - 스크립트 언어로 특수 목적이 아닌 이상 웹 브라우저에 인터프리터가 내장되어 있다. 자바 스크립트는 클라이언트 단에서 웹페이지가 동작하는 것을 담당한다. 구조적으로 비동기 프로그래밍에 유리하다.
짧은 동작의 경우, 절차적 프로그래밍(동기적)을 해도 잘 돌아가 보이지만, 웹 브라우저나 NodeJS 서버에서도 자바스크립트의 비동기 프로그램 작성시에는 스레드를 분기하여 작업을 분산 처리하거나 컨티뉴에이션(+타이머)만 이용해 비동기 프로그램을 구현한다.
Celery는 메시지 브로커와 python 작업 프로세스를 연결해서 이러한 비동기 작업을 수행할 수 있는 시스템을 제공한다.
메시지 브로커는 Redis나 Rabbit MQ라는 데이터베이스를 쓰기 권장하지만, 우리 프로젝트에서는 PostgreSQL을 사용하기로 결정하였다.
Sentiment Analysis
- 문제 상황 유저의 인풋 파일과 관련하여 Sentiment Analysis를 진행할 때, 서버를 동기적으로 구현해놓았기 때문에 분석되는 시간동안 유저는 화면만 로딩 바라보아야 했다.
- 문제 해결 비동기적 프로그래밍을 하기로 결정했다. Celery-비동기 작업큐를 이용하여 해결할 수 있었다. 우리의 메세지 브로커는 RabbitMQ나 Redis가 아닌 PostgreSQL로 정했다. 이 브로커가 유저의 요청을 저장하면, task를 백그라운드의 work에게 할당하는 방식이었다.
- 시간 단축 우리 프로젝트는 현재 4가지의 분석 툴을 제공하는데, 이 분석툴이 순차적으로 진행될 필요는 없다. 그래서 하나의 request당 4명의 자식 worker를 호출하는 방식으로 개발하여 분석 시간을 약 1/4 단축시킬 수 있었다.
Celery - Worker
Starting the worker
$ celery -A proj worker -l info해당 명령어를 통해서 project의 worker를 실행시킬 수 있다.
또한 하나의 머신에서 여러 worker를 실행시킬 수 있는데, 이때 각각의 worker에게 hostname argument를 이용하여 name을 붙여주어야 한다.
Stoping the worker
Shutdown은 term신호를 통해 실행할 수 있다.
종료가 시작되면 worker는 실제로 종료되기 전에, 현재 실행중인 모든 작업을 완료한다. 실행하던 작업이 중요한 경우 KILL신호 전송과 같이 과감한 작업을 수행하기 전에 작업이 완료될 때까지 기다려야 한다.
Worker가 상당한 시간이 지난 후 무한루프 또는 이와 유사한 상태로 갇혀있어 종료되지 않을 때, acks_late 옵션을 설정하고, KILL신호를 사용하여 작업자를 강제 종료할 수 있다.
$ celery -A proj worker --loglevel=INFO --concurrency=10 -n worker1@%h
$ celery -A proj worker --loglevel=INFO --concurrency=10 -n worker2@%h
$ celery -A proj worker --loglevel=INFO --concurrency=10 -n worker3@%h이름이 다른 각각의 worker를 생성해서 같은 머신에서 동작하게 할 수 있다.
Restarting the worker
worker를 재시작하기 위해선, Term 신호를 보내고, 새로운 instance를 시작해야한다.
가장 쉬운 방법은 celery multi 명령어를 이용하는 것이다.
또한 HUP 신호를 이용하여 재시작할 수있다. 하지만 이 방법은 추천되는 방식은 아니다. 또한 이 방식은 macOS에서는 지원되지 않는다.
Celery Handling Test
When the user input file and click the submit Button, the server get all unassigned request list and run celery tasks.
In the tasks, it change the project status ‘unassigned’ to ‘pending’.
And It generate a random number and sleep for that time, And change the project status ‘pending’ to ‘success’.
In this process, I think it is better that when user send a request, the server just execute that request.
There can be a unassigned or failure request, so we make a PostgreSQL checker like a manager and that checker calls the run function for that request.
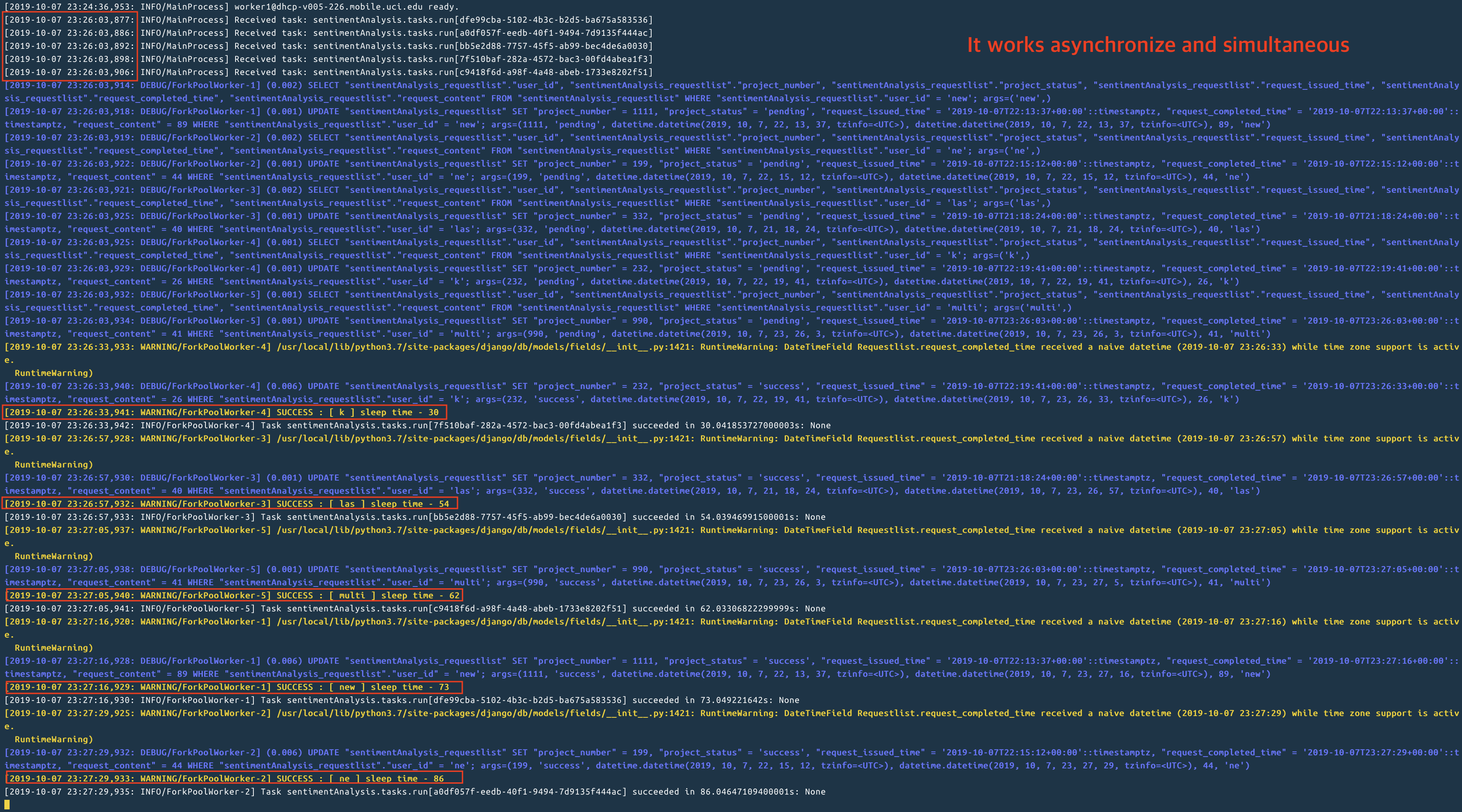
I can’t find the celery get the request list from the PostgreSQL.
Celery Task
delay()
The delay() method is convenient as it looks like calling a regular function.
delay() is clearly convenient, but if I want to set additional execution options, I have to use apply_async().
Linking
The callback task will be applied with the result of the parent task as a partial argument.
add.apply_async((2, 2), link=add.s(16))The result of the first task (4) will be sent to a new task to next function.
I can also cause a callback to be applied if task raises an exception, but this behaves differently from a regular callback in that it will be passed the id of the parent task, not the result. - 결과가 아니라 상위 태스크의 아이디값이 전달된다는 점이 일반 콜백과 다른 점이다.
link를 이용해서 Send Email 기능을 짤 수 있을 것 같다.
Celery Exception Handling
- Linking Error_Handler
@app.task
def error_handler(uuid):
result = AsyncResult(uuid)
exc = result.get(propagate=False)
print('Task {0} raised exception: {1!r}\n{2!r}'.format(
uuid, exc, result.traceback))
add.apply_async((2, 2), link_error=error_handler.s())The error_handler can be added to the task using the link_error execution option.
에러가 발생할 때, project_status를 “Failure”라고 바꿀 것이고, PostgreSQL Listener가 Failure 또는 Unassigned 작업을 처리하도록 구현하면 될 것 같다.
- Get return value
run.delay(unassignedRequest[i].user_id)Now my test code is like this.
I can get a return value like result = run.delay(unassignedRequest[i].user_i).
And I can know the result status.
??? : If celery tasks return any result, Do I have to use get() or forget() function??
- If a Request stuck in an infinite-loop!
-> We can handle this error with Error_Handler(timeout error).
If error is occured, then that function change the project_status “pending” to “failure”.